The New Science
February 1 2024
change is the only constant, people used to say. new year, new job, new people, same old challenges.
last week I was preparing a welcome session, for my new team to know a little more about me. topic I chose was “Continuous Delivery – what I learned in the past 3 years”, which soon turned out to include Continuous Integration as well, as the CI part revealed to be truly relevant for them as well. well, right in time as the original article has just been revamped, with a (more than) 20th years reissue!
anyway, after I’m done presenting the content, and having collected some feedback, I think it also deserves to be shared here. it’s two stories packaged as one. first one is telling you what I learned about CI, how I contributed in adopting the practice on a shared monolithic project — at a department level. then, second one is about my first hand experience with CD, how I supported the adoption within few individual teams.
so, here they come.
Continuous Integration @ E-Commerce
[…] a hundred people, working on a shared legacy monolithic proprietary solution, running on bare metal.
that’s when I paused for a little, after having introduced the main traits of the e-commerce that was paying my salary for the last few years. and that’s why the department already started extracting an internal platform out of it, to be evolved and scaled at a different pace, being under control of individual product teams. let’s keep focusing on the e-commerce first.

at the source-code level, teams decided to keep their own version of the truth, being per-team branches (eg: cicd-team-x), or even per-team forks. on top of them, feature branches were also supposed to be prepared. integrating all those different versions required effort from a dedicated group of people, ensuring no conflict emerged, by composing a release candidate branch (eg: rc-123) from all those contributions. once done, one last branch was there to host final revision to be released (eg: production). that effort was expected to take 2 weeks, as for the Release Train cadence.
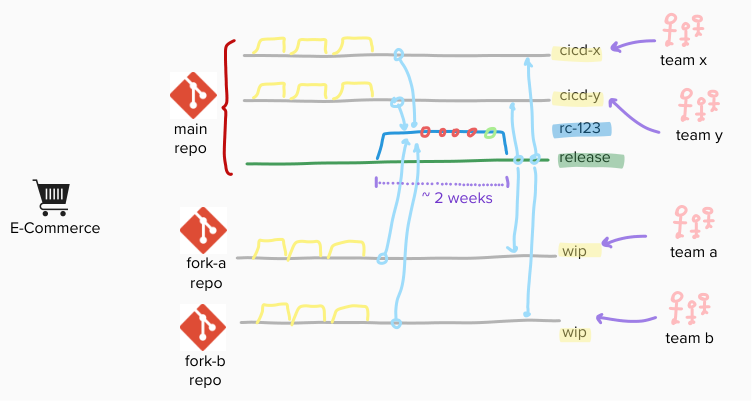
so, for 2 weeks teams were working in isolation, testing their stuff on an individual per-team environment (eg: dev-x), while someone else was preparing, testing and fixing the release candidate on a shared pre-production environment (eg: pp) – until it worked. both automatic end-to-end tests and manual quality assurance were there to prove it.

the process to build any of the aforementioned branches (from main or fork repositories) was simple enough: checkout, build with unit tests, artefact packaged, then finally copied and deployed to remote hosts. on pre-production environment only, few end-to-end tests were then run, while additional non-regression tests were nightly scheduled.
note that, also on the production release day, artefact was going to be re-built from scratch, from production branch, and deployed to every host.

to distinguish configurations between deployments to non-production and production environments, being run by the very same automation, we relied on per-environment config files, included in the artefact, versioned within the application source code itself. little change in a config file required the full automation process to be executed again: checkout, build, package (here the only difference) and finally deploy.
[..] hope no children is hearing this, as it all sounds like scary movie!
that’s when I realised I could jump in and contribute, to what was the early stage of a Community Of Practice (CoP) on Software Infrastructure, which took its baby steps right before I joined. luckily, people started asking good questions. for example: is there any simpler process? can we anticipate the feedback? why can’t we just apply common practices?
it took few months, from incubating to delivering, but finally we settled on a shared mainline: all teams, with one only truth – a mastermaster.
daily, not bi-weekly. hooray!

in order to prevent untested code to be released, in production or even pre-production environments, we relied on the alternatives available (probably ignoring they were named so): “keystone interface”, “branch by abstraction” and of course, feature toggles. an in-house dedicated internal and public facing API had already been developed for this, while also per-environment configurations worked sometime (when waiting for two weeks to toggle on was affordable).
in addition to that, a new shared dev environment was prepared, in order to anticipate the feedback. it was intended to be both an integration sandbox for teams, by manually deploying master when needed, multiple times a day, and the target for an an automatic deployment, once a day.
those daily deployments where scheduled so that we could get master deployed on dev early in the morning (sometimes getting welcomed by “good morning, please remember to fix the build!”), and the release candidate (aligned with master) on pp in the mid afternoon. so that manual UAT and automatic e2e could then be performed, lately.

to recap, our feedback loops where:
master: build, test and package – on every commitmaster: build, test, package and deploy todev– everyday, early in the morning- release candidate (aligned with
master): build, test, package, deploy topp, e2e tests – everyday, in the afternoon - release candidate (aligned with
master): non-regression tests – everyday, all night long
that is: simple enough to work, simple enough to be agreed upon. but even so, it took multiple weeks to be refined, and applied by all teams (product, operations).
you would probably suggest it could be simpler: no release candidate branch, for example; no manual daily alignment; no per-team dev environments, anymore. or that we could push it even more: automatic deployment to dev, with end-to-end tests, on every commit.
you’re right.
but too big change in one shot, wouldn’t probably have worked. remember, about a hundred people involved. they should have had proper time, to test and conquer the new daily routines. this process was fitting like a “glue” between what people were used to do, and what we aimed to achieve with a proper CI approach. focusing on having people willing to integrate to master frequently, we decided to provide a quick feedback loop, to gain confidence on the process (deployment to dev and e2e tests would have added 30 minutes or so).
perfect is the enemy of good, you also say. and you’re still right!
what I re-learned, is that Continuous Integration is not a tool, but a practice. it’s the intent of getting frequent feedback (at least daily) from integrating all the contributions to a shared mainline. and that the hard part is on people, not on tools (again). but we value people, more than tools, don’t we?
if you’re still with me, not yet bored, keep reading on. next story is about Continuous Delivery.
Continuous Delivery @ Platform
in addition to the legacy e-commerce, an internal digital platform was also already there, composed by micro-frontends and micro-services providing user experiences such as searches, accounts, checkout, and the like. each user experience was in the hand of one to few teams.
at the source-code level, things were drastically better: every repository had a master branch acting as a shared mainline, with frequent integrations, directly on it or with short-lived feature branches (depending on the confidence every team had). a production branch was there, with the only intent of tracking current released version (so, more like a tagging mechanism).

daily, we had deployments on a shared dev environment (being master or feature branches), with automatic end-to-end tests. next in line, a pre-production environment was there to host features to be manually tested as part of UAT. finally, a production environment was waiting our deployments. at least weekly, as the typical pace within most of the teams.
so, at the CI level, so far – so good!

from the very first week working on this setup, I was wondering why did we need to track current release at the source-code level. can’t we ask live system this question? hey production, what’s your version? and what about you, pre-production? unfortunately, we could not. as part of the deployment, we had no reference to the application version whatsoever. duh!
but to show you why, I need to dig a little deeper in how we were using the selected deployment infrastructure: ECS with Fargate, which is the “fully managed” / “no operations” proprietary container orchestration offering from AWS.
its deployment descriptor is called task definition, versioned as an ECS resource. to deploy an updated task definition, you create a new version first, and start a deployment then. to a certain extent, task definitions are “provisioned” resources, and so we initially managed them as part of our provisioning strategy, with an Infrastructure as Code tool such as Terraform.
typical blueprint for one of our applications (services or frontends) was:
- docker image tags named after target environments. eg:
service:dev,service:ppandservice:prd - per-environment plain configurations as environment variables, bound to external SSM parameters. eg:
DB_URLbound todev-dburl,pp-dburlorprd-dburlparameters - per-environment sensitive configurations as environment variables, bound to external SSM secrets. eg:
DB_PSWbound todev-dbpsw,pp-dbpsworprd-dbpsw
so, not only SSM secrets values, but also SSM parameters values where manually managed on AWS (even if provisioned by Terraform). of course, here “manually” means “programmatically”, by command line: every value change was achieved by executing an aws ssm put-parameter --overwrite command, from our laptops.
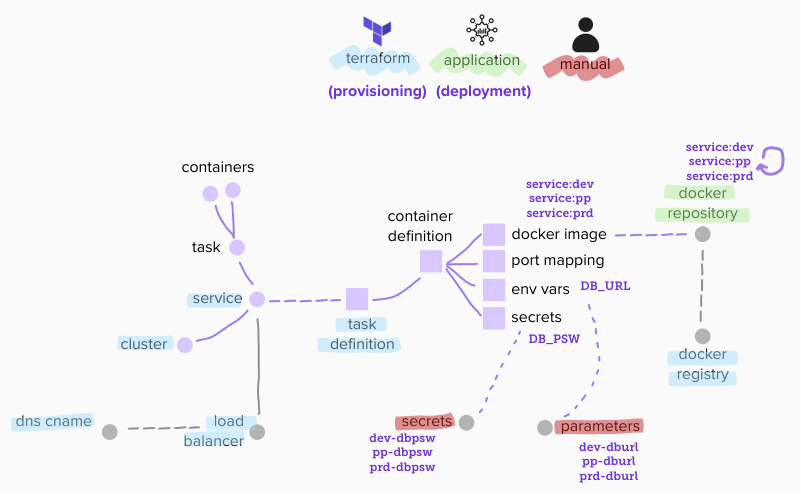
for every environment, we had a dedicate automation, with slightly few differences, if not only the source branch, the target environment and the docker image tag. steps were: checkout a branch, build with unit tests, package the artefact, publish on docker registry and finally deploy. end-to-end tests were also performed, except for production.
so, now it should be clear. deploy was actually just requesting ECS to “force a new deployment”, on the existing service, so with the very same docker image tag (eg: service:dev). some magic was ensuring same tag resulted in the latest version of that tag being actually pulled (this is the default behaviour of Fargate – not caching docker images – while on EC2 it’s not).
what a magic!

“immutable” task definitions, no deployment without a build, and manually updated configurations. that was really slowing down the feedback loop. here’s an example.
imagine you were working on a new feature, and a new configuration was required (eg: the URL for a new API to be consumed). so you had to:
- introduce a new environment variable, to be read by the application (in the source code)
- extend deployment manifest for reading that environment variable, from a new SSM parameter, named after each environment (all of this, on Terraform)
- manually prepare new SSM parameter, for every environment (by CLI)
- build and deploy the application, with per-environment pipelines. docker image tag would get updated, pushed first and then pulled
then, imagine you got the wrong URLs, and had to update them in every environment! gosh, you than had to:
- manually update SSM parameters, for every environment
- build and deploy the application, with per-environment pipelines
please note, automations were going to perform the whole process, from checking out the source code, building and testing, packaging and finally deploying. this time, very same docker image tag, very same SSM parameters names, only new SSM parameters values had to actually be updated.
that’s when I started wondering if anything better could be achieved.
by focusing on what was slowing down the feedback process, I quickly set my goal in exploring three pillars:
- deploy application version. each artefact would be identified and deployed by its unique version (eg: build number + commit hash)
- build once, deploy everywhere. each version would be promoted across all environments, from
devtoprd - configuration as part of deployment, not provisioning. no need to interact with Terraform to update any configuration, commit + re-deploy would be enough (same artefact version, deployment descriptor with new configuration values)
in other words, every commit would be a potential release. that sounded like my personal definition of Continuous Delivery, finally.
that means, we don’t need (nor want) to track releases in the code itself: every commit is, potentially. so at the source-code level, the only change was getting rid of the production branch.

that was also required, in order to align automations for deploying to any environment (meaning, no more production branch as the only source for deploying to prd).
then, by investigating the state of the art about Terraform managed ECS task definitions, and the attempt to have individual docker image versions, I found it was an hot topic. for example, this discussion provided a lot of context: people were concerned about it since 2017, and yet not definitive approach was proposed at that time (early 2021). but luckily, few open-source contributions were already available.
one of them was silinternational/ecs-deploy, which allowed having deployment descriptors (task definitions) as “input” of the deployment process, versioned as part of the application codebase. then, by combining it with a template engine to dynamically bake the deployment descriptor (for example noqcks/gucci – a standalone Go template engine), basically I was done. I could create a deployment descriptor at deploy time, from a versioned template, by setting per-environment configuration values.
bingo!

deploying the very same artefact version in a specific environment, was a matter of choosing target environment, and a values file, to be read at deployment time. being the same process, we could iterate it. so, after we deployed on dev, for quick feedback from the end-to-end tests, we could then decide to promote to pp, re-execute the same end-to-end tests and be ready in performing some UAT.
great. one only automation, to process every commit we were pushing on the shared mainline: building, testing, packaging, and the CI part was done. then, CD would kick in, by deploying the very same version to dev, testing it, then promoting to pp, and testing it. then, a manual approval to prd, as for the definition of Continuous Delivery: no need to automatically go straight to production, as it would have been with Continuous Deployment. instead, we resumed the pipeline, to proceed with prd, once UAT was successful.
(initially, we had a manual approval from dev to pp also, which we later dismissed, and found that caused no harm at all!)
and that revealed to be a great foundation, as we also took the chance to enrich the pipeline with additional feedbacks, such as integration tests (focusing on external services integrations, in isolation – allowed to fail when external parties were unavailable), static code analysis, security check and, finally, performance tests.

worth mentioning, we also enjoyed yet another strategy for incremental rollout: dark launches, by silently enabling new features in production, executing them but providing no feedback to users, while collecting results instead and measuring impact. for example, executing old and new versions of an API in parallel, comparing results (from telemetry data such as logs and distributed traces), before actually migrating to the new one.
great, we’re almost done.
just for you to know, we finally had the chance to give back to the Open Source community what we learned, by releasing our internal tooling. you can find more about it here and here.
and that was part of the learning as well. not only the attempt of splitting what was publicly disclosable, from what was to still keep internal. but also in the process of making something valuable to the crowd: templates, samples, experimental features (such as support for Canary Releases) and lot of documentation.
for example, we improved our per-environment configurations strategy, by using application configuration overrides instead of environment variables (as the complexity increased and adding new configurations became a typo-prone process). that of course was leveraging on specific mechanisms, for different technologies, and we promptly documented those we adopted, covering much of our tech stack (Ktor, Spring Boot, ReactJS, etc). there’s a dedicated section in the EXTRA.
nice, we’re done. really.
Reprise
change is the only constant, people still use to say. new everything, but still the same old challenges.
history is cyclical, as the ancient philosopher Giambattista Vico once said, in his famous work “The New Science”. and that’s the link, if you have maybe been wondering, all through this long and exhausting reading.
science, which, as in Dave Farley’s words (one of the Continuous Delivery’s fathers), has to be applied. to achieve software engineering.

April 28 2024 at 3:29 pm
[…] on the “what I learned in the past few years about Continuous Delivery” series, which I kicked off early this year. today’s focus is on some techniques I was able to test, with my past team, […]